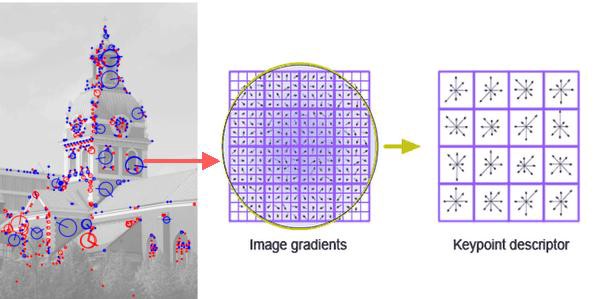
Traditional way of feature extraction
Computer vision can be succinctly described as finding and telling features from images to help discriminate objects and/or classes of objects.
Computer vision has become one of the vital research areas and the commercial applications bounded with the use of computer vision methodologies is becoming a huge portion in industry. The accuracy and the speed of processing and identifying images captured from cameras are has developed through decades. Being the well-known boy in town, deep learning is playing a major role as a computer vision tool.
Is deep learning the only tool to perform computer vision?
A big no! Deep learning came to the scene of computer vision couple of years back. Back then, computer vision was mainly based with image processing algorithms and methods. The main process of computer vision was extracting the features of the image. Detecting the color, edges, corners and objects were the first step to do when performing a computer vision task. These features are human engineered and accuracy and the reliability of the models directly depend on the extracted features and on the methods used for feature extraction. In the traditional vision scope, the algorithms like SIFT (Scale-Invariant Feature Transform), SURF (Speeded-Up Robust Features), BRIEF (Binary Robust Independent Elementary Features) plays the major role of extracting the features from the raw image.
The difficulty with this approach of feature extraction in image classification is that you have to choose which features to look for in each given image. When the number of classes of the classification goes high or the image clarity goes down it’s really hard to cope up with traditional computer vision algorithms.
The Deep Learning approach –
Deep learning, which is a subset of machine learning has shown a significant performance and accuracy gain in the field of computer vision. Arguably one of the most influential papers in applying deep learning to computer vision, in 2012, a neural network containing over 60 million parameters significantly beat previous state-of-the-art approaches to image recognition in a popular ImageNet computer vision competition: ISVRC-2012
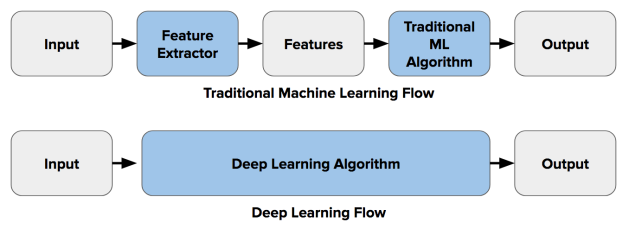 The boom started with the convolutional neural networks and the modified architectures of ConvNets. By now it is said that some convNet architectures are so close to 100% accuracy of image classification challenges, sometimes beating the human eye!
The boom started with the convolutional neural networks and the modified architectures of ConvNets. By now it is said that some convNet architectures are so close to 100% accuracy of image classification challenges, sometimes beating the human eye!
The main difference in deep learning approach of computer vision is the concept of end-to-end learning. There’s no longer need of defining the features and do feature engineering. The neural do that for you. It can simply put in this way.
If you want to teach a [deep] neural network to recognize a cat, for instance, you don’t tell it to look for whiskers, ears, fur, and eyes. You simply show it thousands and thousands of photos of cats, and eventually it works things out. If it keeps misclassifying foxes as cats, you don’t rewrite the code. You just keep coaching it.
Though deep neural networks has its major drawbacks like, need of having huge amount of training data and need of large computation power, the field of computer vision has already conquered by this amazing tool already!

Pingback: Roadmap to Computer Vision Towards Data Science – Medium – DeFi News
Pingback: THE BLOG MEDIA - LATEST DAILY TRENDS ON THE GO | 24/7 UPDATED CONTENTS.......
Pingback: Roadmap to Computer Vision – The Open Bootcamps
Pingback: Roadmap to Computer Vision – Cooding Dessign
Pingback: Roadmap to Computer Vision - AI & Machine Learning | Experfy Insights
Pingback: 10 Tips for Designing & Developing Computer Vision Projects | NaadiSpeaks