 Data is the king in machine learning. In the process of building machine learning models, data is used as the input features.
Data is the king in machine learning. In the process of building machine learning models, data is used as the input features.
Input features comes in all shapes and sizes. For building a predictive model with a better accuracy rate, we should understand the data as well as the logic behind the algorithm we going to use to fit the model.
Data Understanding; as the second step of CRISP-DM, guides for understanding the types and the way the data we get has been represented. We can distinguish three main kinds of data feature.
- Quantitative Data – Data with numerical scale (Age of a person in years, Price of a house in dollars etc.)
- Ordinal features – Data without a scale but with ordering (Ordered sets/ first, second, third etc.)
- Categorical features – Data without a numerical scale neither an ordering. These features don’t allow any statistical summary. (Car manufacturer categories, Civil status, N-grams in NLP etc.)
Most of the machine learning algorithms such as linear regression, logistic regression, neural network, support vector machine works better with numerical features.
Quantitative features come with a numerical value and they can be directly used (Sometimes data preprocessing, normalization may have to use) as the input features of ML algorithms.
Ordinal features can be easily represented in numbers (Ex. First = 1, Second = 2, Third = 3 …). This is called Integer Encoding. Representing ordinal features using numbers makes sense because the dependency between each representation can be notated in a numerical way.
There are some algorithms that can directly deal with joint discrete distribution such as Markov chain / Naive Bayes / Bayesian network, tree based, etc. These algorithms can work with categorical data without any encoding; while we should encode the categorical features in a way to represent in a numerically to use as the input features for other ML algorithms. That means it’s better to change the categorical features to numerical most of the times 😊
There are some special cases too. For an example, while naïve bias classification only really handles categorical features, many geometric models go in the other direction by only handling quantitative features.
How to convert Categorical data for Numerical data?
There are few ways to covert the categorical data to numerical data.
- Dummy encoding
- One-hot encoding / one-of-K scheme
are the most prominent ways of it.
One hot encoding is the process of converting the categorical features into numerical by performing “binarization” of the category and include it as a feature to train the model.
In mathematics, we can define one-hot encoding as…
One hot encoding transforms:
a single variable with n observations and d distinct values,
to
d binary variables with n observations each. Each observation indicating the presence (1) or absence (0) of the dth binary variable.
Let’s get this clear with an example. Suppose you have ‘flower’ feature which can take values ‘daffodil’, ‘lily’, and ‘rose’. One hot encoding converts ‘flower’ feature to three features, ‘is_daffodil’, ‘is_lily’, and ‘is_rose’ which all are binary.
 A common application of OHE is in Natural Language Processing (NLP). It can be used to turn words to vectors so easily. Here comes a con of OHE, where the vector size might get very large with respect to the number of distinct values in the feature column.If there’s only two distinct categories in the feature, no need to construct to additional columns. You can just replace the feature column with one Boolean column.
A common application of OHE is in Natural Language Processing (NLP). It can be used to turn words to vectors so easily. Here comes a con of OHE, where the vector size might get very large with respect to the number of distinct values in the feature column.If there’s only two distinct categories in the feature, no need to construct to additional columns. You can just replace the feature column with one Boolean column.
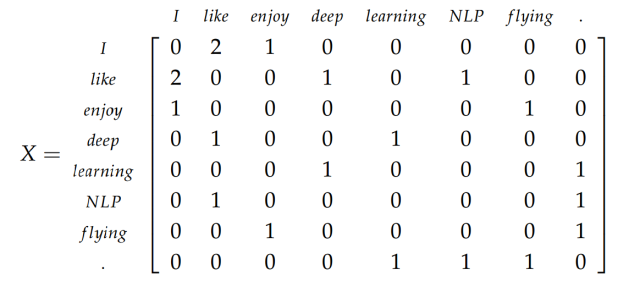
OHE in word vector representation
You can easily perform One-hot encoding in AzureML Studio by using the ‘Convert to Indicator Values’ module. The purpose of this module is to convert columns that contain categorical values into a series of binary indicator columns that can more easily be used as features in a machine learning model, which is the same happens in OHE. Let’s look at performing One-Hot encoding using python in next article.
 When it comes to a machine learning or data science related problem, the most difficult part would be finding out the best approach to cope up with the task. Simply to get the idea of where to start!
When it comes to a machine learning or data science related problem, the most difficult part would be finding out the best approach to cope up with the task. Simply to get the idea of where to start!
 2017 ended up making ‘chatbots’ not a trend but an essential in the tech world. With the rise of chatbots, building up effective natural language understanding (NLU) models is a must. LUIS is an admirable service from Microsoft Cognitive Services that can use for building NLU models.
2017 ended up making ‘chatbots’ not a trend but an essential in the tech world. With the rise of chatbots, building up effective natural language understanding (NLU) models is a must. LUIS is an admirable service from Microsoft Cognitive Services that can use for building NLU models.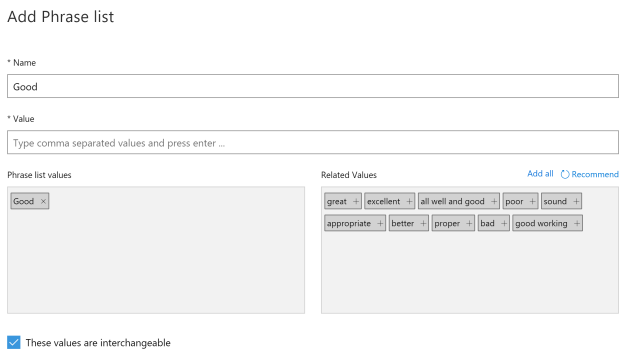 Another use of the Phrase list is to train the model the domain specific words. As an example, you can add a list of fruit names (Apple, Orange, Grapes) to a phrase list and give it a name. It’ll help the LUIS model to align according to the given domain.
Another use of the Phrase list is to train the model the domain specific words. As an example, you can add a list of fruit names (Apple, Orange, Grapes) to a phrase list and give it a name. It’ll help the LUIS model to align according to the given domain.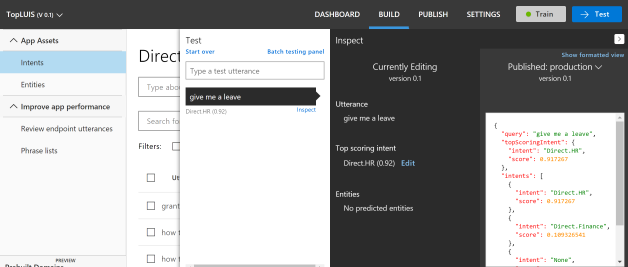

 For the safe side, use python virtual environments. It would avoid many hassles occurs with library dependencies. I’ve used anaconda environment as the base of virtual environment.
For the safe side, use python virtual environments. It would avoid many hassles occurs with library dependencies. I’ve used anaconda environment as the base of virtual environment.
 Here the API operates through POST methods which accepts the input in JSON.
Here the API operates through POST methods which accepts the input in JSON.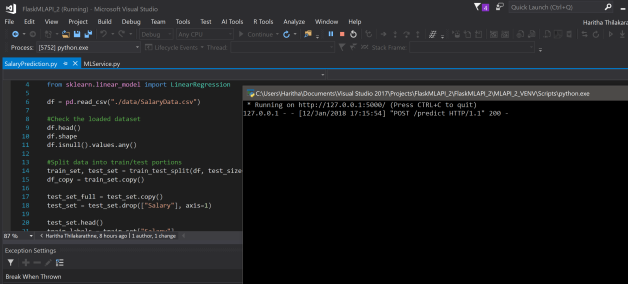

 No need to purchase Visual Studio enterprise or ultimate. The freely available Visual Studio Community edition works fine. In 2017 version python comes along side with the default installation options. For the later versions you need to install Python Tools for Visual Studio (PTVS) separately.
No need to purchase Visual Studio enterprise or ultimate. The freely available Visual Studio Community edition works fine. In 2017 version python comes along side with the default installation options. For the later versions you need to install Python Tools for Visual Studio (PTVS) separately.

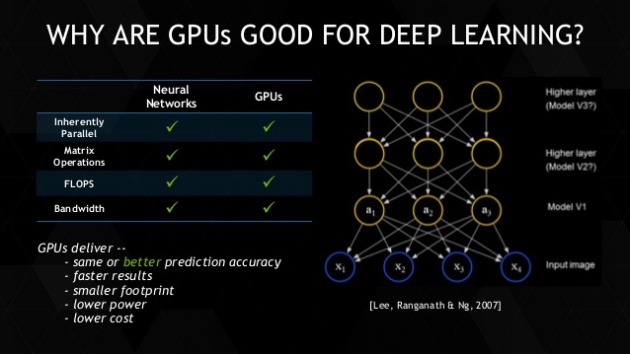


 The word ‘chatbots’ has become one of the most whispered words in the tech world today. Each and every tech company is putting a lot of effort on researching and developing bot related technologies.
The word ‘chatbots’ has become one of the most whispered words in the tech world today. Each and every tech company is putting a lot of effort on researching and developing bot related technologies.
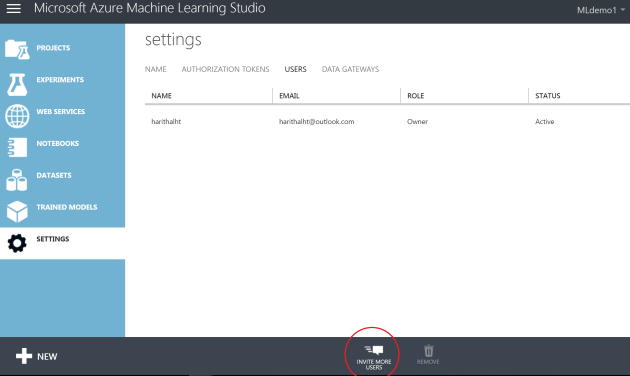 The users you inviting should have a Microsoft account or a work/school account from Azure Active Directory. Two user access levels can be defined as “Users” and “Owners”.
The users you inviting should have a Microsoft account or a work/school account from Azure Active Directory. Two user access levels can be defined as “Users” and “Owners”.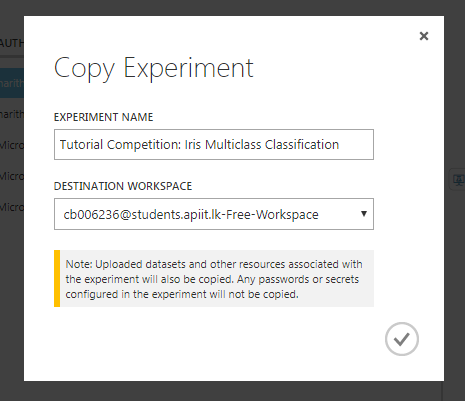 You’ll not be able to copy multiple experiments using a single click. If you have such kind of scenario, use poweshell scripts as instructed in this
You’ll not be able to copy multiple experiments using a single click. If you have such kind of scenario, use poweshell scripts as instructed in this 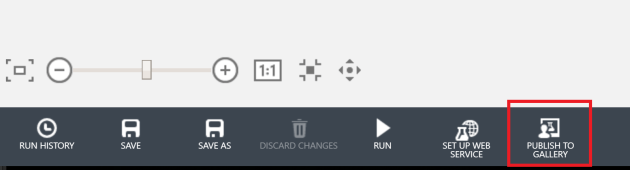 For me this is one of the most useful options. You can use this option in two ways. One is to make the experiments public and in a way that only accessible through a shared link. If you share the experiment publicly that will be listed in the Cortana Intelligence Gallery.
For me this is one of the most useful options. You can use this option in two ways. One is to make the experiments public and in a way that only accessible through a shared link. If you share the experiment publicly that will be listed in the Cortana Intelligence Gallery.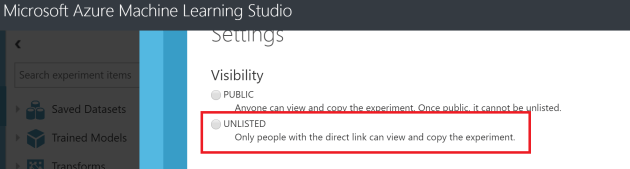 If you want to share an experiment only with your peer group, publishing as an ‘unlisted’ experiment is the best way. Users can open the experiment in their own AzureML studio. This option can be used to migrate your experiment within different workspaces as well as between different azure regions. Only the users who’s having the link you shared can only view or use the experiment you shared.
If you want to share an experiment only with your peer group, publishing as an ‘unlisted’ experiment is the best way. Users can open the experiment in their own AzureML studio. This option can be used to migrate your experiment within different workspaces as well as between different azure regions. Only the users who’s having the link you shared can only view or use the experiment you shared.