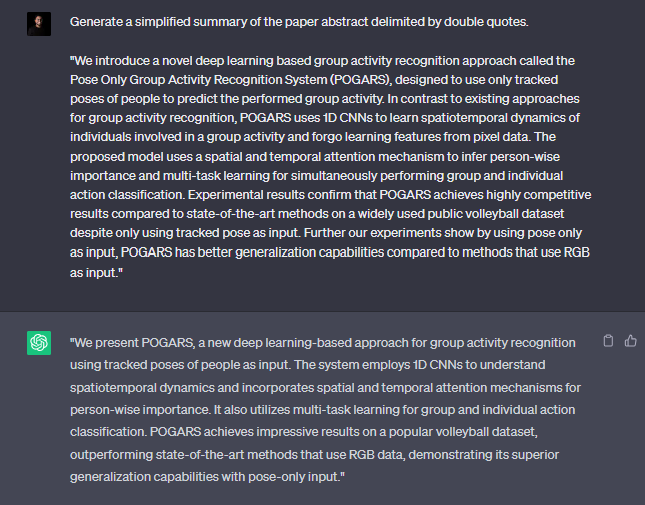
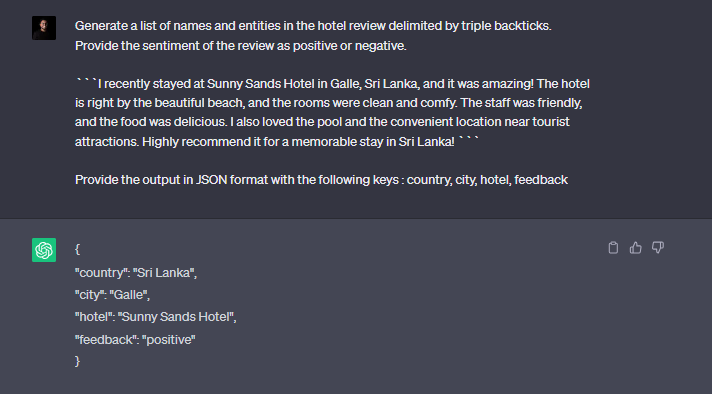
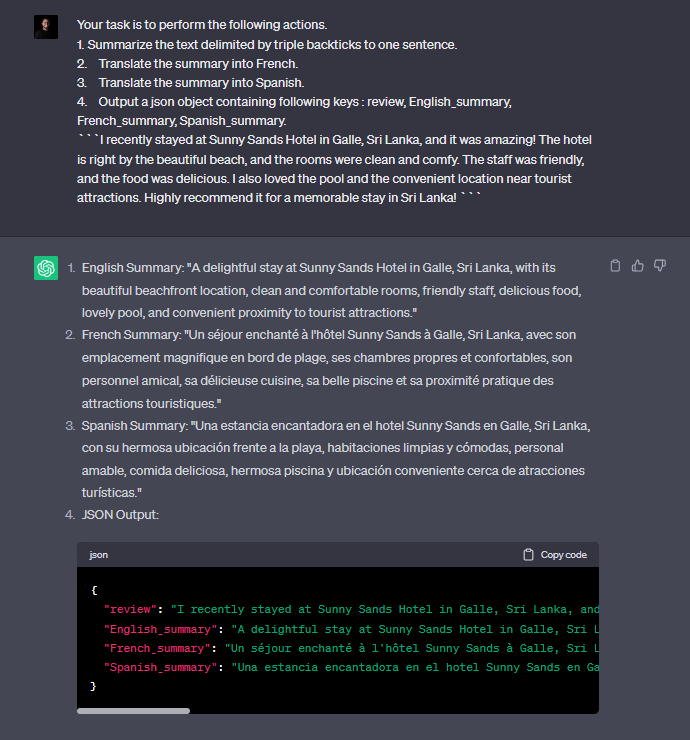
Yes. This is all about the hype of ChatGPT. It’s obvious that most of us are too obsessed with it and spending a lot of time with that amazing tool even as the regular search engine! (Is that a bye-bye google? 😀 )
I thought of discussing the usage of underlying mechanics of ChatGPT: Large Language Models (LLMs) and the applicability of these giants in intelligent application development.
What actually ChatGPT is?
ChatGPT is a conversational AI model developed by OpenAI. It uses the GPT-3 architecture, which is based on Transformer neural networks. GPT-3 is large language model with about 175 billion parameters. The model has been trained on a huge corpus of text data (about 45TB) to generate human-like responses to text inputs. Most of the data used in training is harvested from public internet. ChatGPT can perform a variety of language tasks such as answering questions, generating text, translating languages, and more.
ChatGPT is only a single use case of a massive research. The underlying power is the ANN architecture GPT-3. Let’s dig down step by step while discussing following pinpoints.
What are Large Language Models (LLMs)?
LLMs are deep learning algorithms that can recognize, summarize, translate, predict and generate text and other content based on knowledge gained from massive datasets. As the name suggests, these language models are trained with massive amounts of textual data using unsupervised learning. (Yes, there’s no data labelling involved with this). BLOOM from Hugging Face, ESMFold from Meta AI, Gato by DeepMind, BERT from Google, MT-NLG from Nvidia & Microsoft, GPT-3 from OpenAI are some of the LLMs in the AI space.
Large language models are among the most successful applications of transformer models. They aren’t just for teaching machines human languages, but for understanding proteins, writing software code and much more.
What are Transformers?
Transformers? Are we going to talk about bumblebee here? Actually not!
Transformers are a type of neural network architecture (similar as Convolutional Neural Networks, Recurrent Neural Networks etc.) designed for processing sequential data such as text, speech, or time-series data. They were introduced in the 2017 research paper “Attention is All You Need“. Transformers use self-attention mechanisms to process the input sequence and compute a weighted sum of the features at each position, allowing the model to efficiently process sequences of varying length and capture long-range dependencies. They have been successful in many natural language processing tasks such as machine translation and have become a popular choice in recent years.
For a deep learning enthusiast this may sound familiar with the RNN architecture which are mostly used for learning sequential tasks. Unless the RNNs, transformers are capable of capturing long term dependencies which make them so capable of complex natural language processing tasks.
GPT stands for “Generative Pre-trained Transformer”. As the name implies it’s built with the blessing of transformers.
Alright… now GPT-3 is the hero here! So, what’s cool about GPT-3?
- GPT-3 is one successful innovation in the LLMs (It’s not the only LLM in the world)
- GPT-3 model itself has no knowledge; its strength lies in its ability to predict the subsequent word(s) in a sequence. It is not intended to store or recall factual information.
- As such the model itself has no knowledge, it is just good at predicting the next word(s) in the sequence. It is not designed to store or retrieve facts.
- It’s a pretrained machine learning model. You cannot download or retrain the model since it’s massive! (fine-tuning with our own data is possible).
- GPT-3 is having a closed-API access which you need an API key to access.
- GPT-3 is good mostly for English language tasks.
- A bit of downside: the outputs can be biased and abusive – since it’s learning from the data fetched from public internet.
If you are really interested in learning the science behind GPT-3 I would recommend to take a look on the paper : Language Models are Few-Shot Learners
What’s OpenAI?
The 2015 founded research organisation OpenAI is the creators of GPT-3 architecture. GPT-3 is not the only interesting innovation from OpenAI. If you have seen AI generated arts which are created from a natural language phrases as the input, it’s most probably from DALL-E 2 neural network which is also from OpenAI.
OpenAI is having there set of APIs, which can be easily adapted for developers in their intelligent application development tasks.
Check the OpenAI APIs here: https://beta.openai.com/overview
What can be the use cases of GPT-3?
We all know ChatGPT is ground-breaking. Our focus should be exploring the approaches which we can use its underlying architecture (GPT-3) in application development.
Since the beginning of the deep neural networks, there have been lot of research and innovation in the computer vision space. The networks like ResNet were ground-breaking and even surpass the human accuracy level in tasks like image classification with ImageNet dataset. We were getting the advantage of having pre-trained state-of-the-art networks for computer vision tasks without bothering on large training datasets.
The LLMs like GPT-3 is addressing the gap of the lack of such networks in natural language analysis tasks. Simply it’s a massive pre-trained knowledge base that can understand language.
There are many interesting use cases of GPT-3 as a language model in use cases including but not limited to:
- Dynamic chatbots for customer service use cases which provide more human-like interaction with users.
- Intelligent document management by generating smart tagging/ paraphrasing, summarizing textual documents.
- Content generation for websites, new articles, educational materials etc.
- Advance textual classification tasks
- Sentiment analysis
- Semantic search capabilities which provide natural language query capability.
- Text translation, keyword identification etc.
- Programming code generation and code optimisation
Since the GPT-3 can be fine-tuned with a given set of training data, the possibilities are limitless with the natural language understanding capability it is having. You can be creative and come up with the next big idea which improves the productivity of your business.
What is Azure OpenAI?
Azure OpenAI is a collaboration between Microsoft’s Azure cloud platform and OpenAI, aimed at providing cloud-based access to OpenAI’s cutting-edge AI models and tools. The partnership provides a seamless platform for developers and organizations to build, deploy, and scale AI applications and services, leveraging the computing resources and technology of the Azure cloud.
Users can access the service through REST APIs, Python SDK or through the Azure OpenAI Service Studio, which is the web-based interface dedicated for OpenAI services.
In enterprise application development scenarios, using OpenAI services through Azure makes it much easier for integration.
Azure OpenAI opened for general availability very recently and I’m pretty sure there’ll be vast improvements in the coming days with the product.
Let’s keep our eyes open and start innovating on ways which we can use this super-power wisely.